Whatever It Is,
We Can Structure It.
We Can Structure It.
Transform complex, unstructured data into clean, structured data. Securely. Continuously. Effortlessly.



Trusted by 87% of
the Fortune 1000.
the Fortune 1000.







ETL so much more.
Security and compliance? Built in. Role-based access? Handled. We take care of all the things that slow teams down so you can focus on unlocking the full potential of your data.
- 64+ File Types
- Chunking, Enrichment, Embedding
- Open AI, Anthropic, + more Integrations
With fast speeds, and seamless partner integrations, our transformation is optimized for any destination.
Transform over 64 different file types.
Grab one of the files below and watch Unstructured turn messy data into clean, structured output, ready for AI and analysis.


Drop a file here




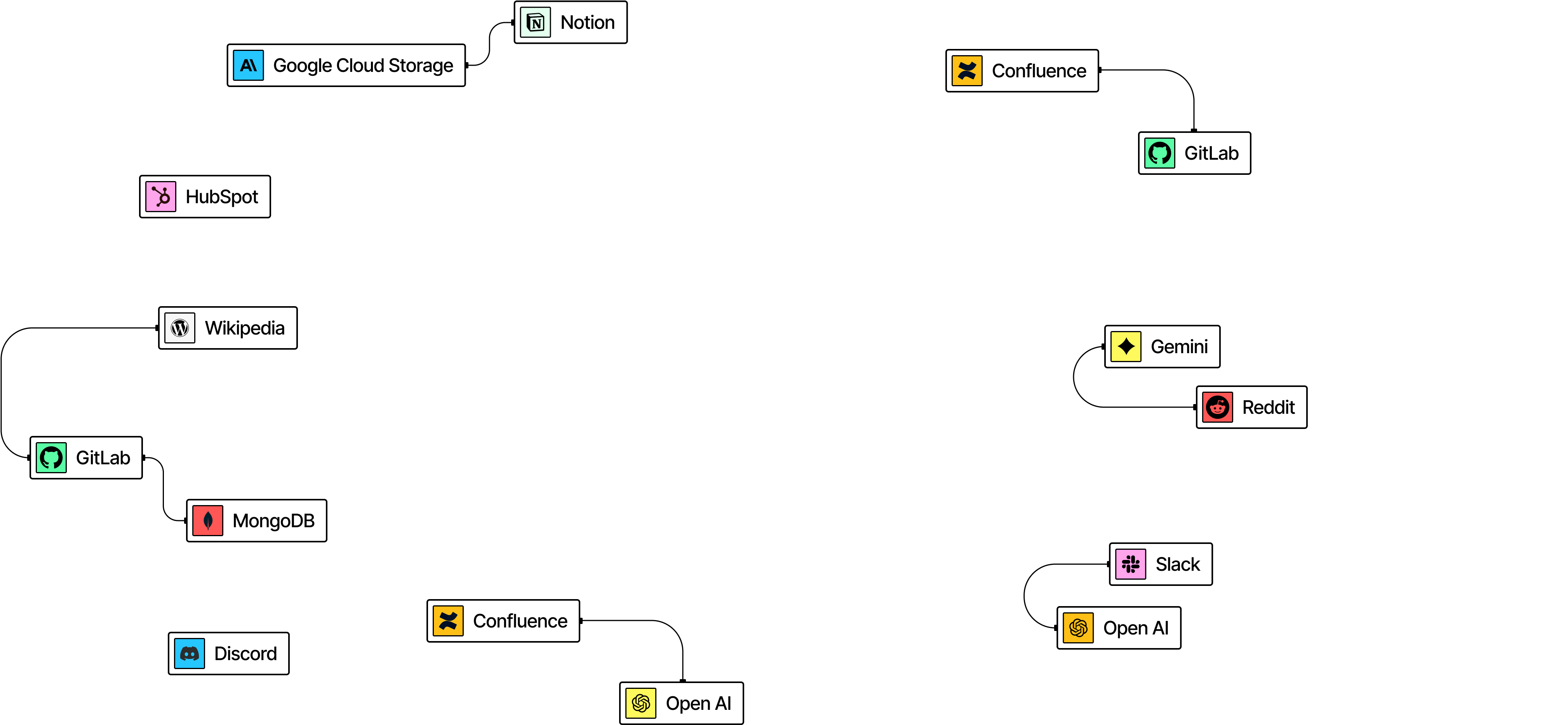
Built to connect.
Designed to scale.
Designed to scale.
With 30+ connectors and 1,250+ pipelines, we seamlessly integrate with any database, data lake, or enterprise system. And because connections should, you know, stay connected, our 24/7 maintenance ensures your pipelines stay reliable as systems evolve.

Just because you can build it, doesn't mean you should.
Building your own document processing pipeline starts simple—but scaling it is another story. What begins as a few scripts and connectors quickly turns into a tangled mess of maintenance, custom fixes, and never-ending updates. Unstructured replaces the DIY rat’s nest so you can focus on AI innovations that move your business forward.
Interface options
for everyone.
for everyone.
Rather click through it yourself? There’s a UI for that. Rather your agent just handle it? There’s an MCP for that.
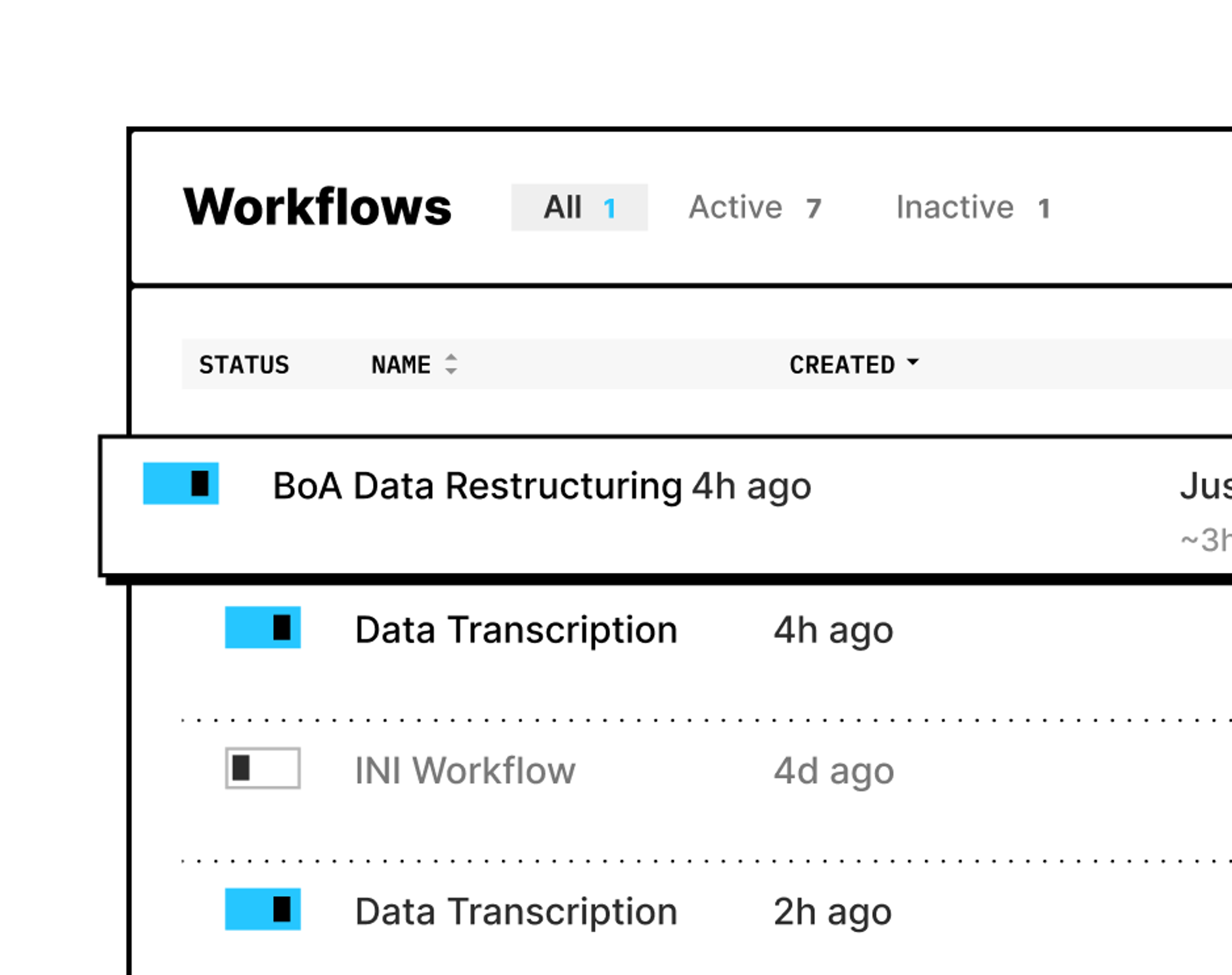
UI
Our UI makes it easy for teams to process and transform data without heavy coding.
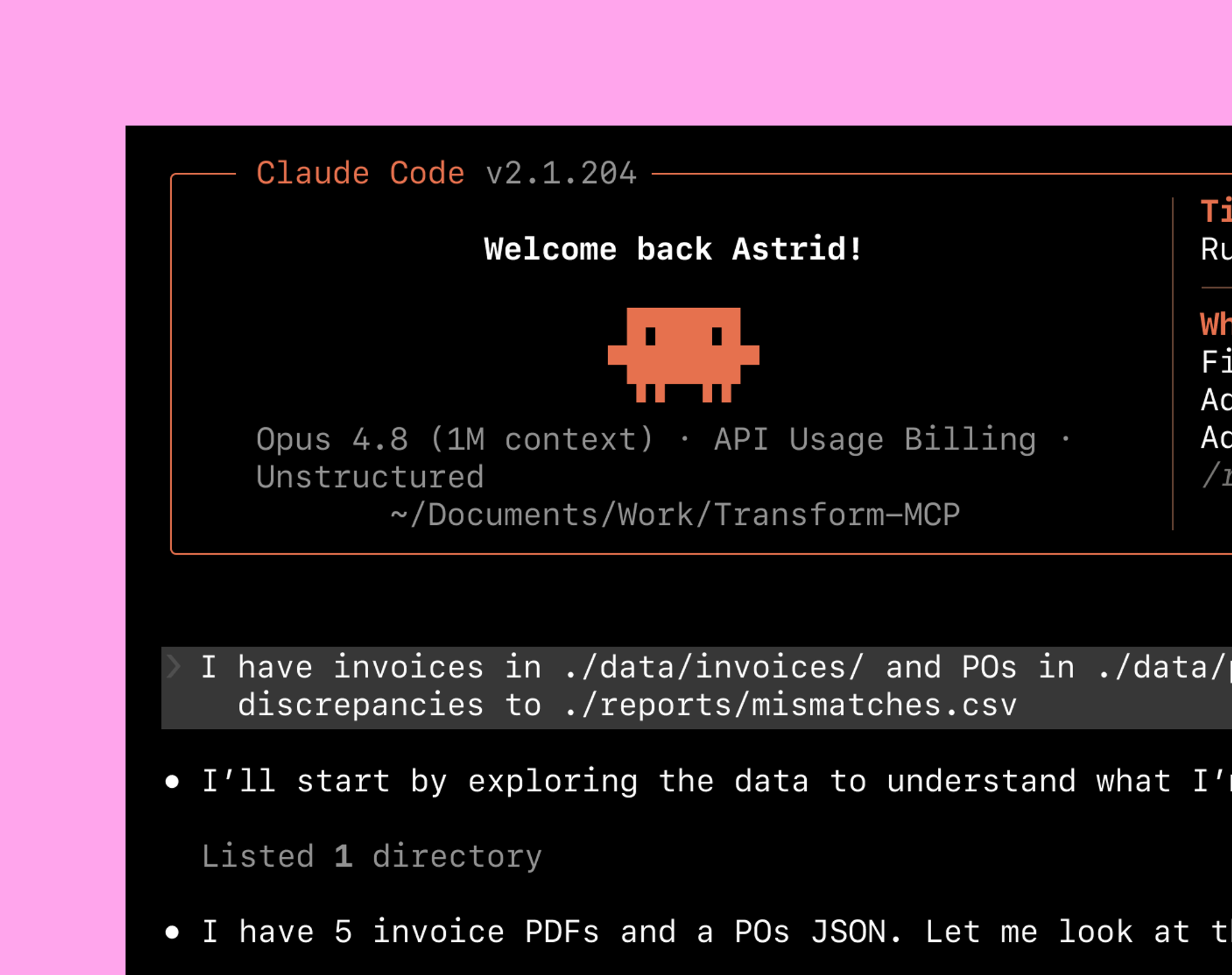
MCP
Document parsing built for agents. One call in Claude Code, Cursor, or Codex, and structured data lands in context.
Data delivered to your doorstep.







If you’re already storing your data with one of our trusted partners, integrating Unstructured into your preprocessing workflow is effortless. Get started with one of our partner setup guides and you'll be up and running in no time.
Ready for
a demo?
a demo?
See how Unstructured simplifies data workflows, reduces engineering effort, and scales effortlessly. Get a live demo today.